Highly Scalable, Ultra-Fast and Lots of Choices

Column Family Store
Your application collects masses of little-structured data that is read more often than written.
Your application may evaluate metrics about user operations or generate reports on business data. This kind of functionality typically includes analytical operations such as calculating aggregates and minimum or maximum values.
Your application needs quick response times when analyzing masses of data. After some data has been collected, the data must show quickly in the analysis.
The traditional solution to analyze data is to set up a data warehouse. The data is stored in a normalized schema in one relational database. For the analysis, it is transformed into a denormalized star schema and transferred into a separate database. Queries on a data warehouse are fast and don't harm the main database's performance. But extracting and transferring data from one database to another is complicated, inefficient and error-prone. The transfer itself is time-consuming so that it may take a long time until new or updated data shows up.
Without a data warehouse, you would need to analyze the data in the main database. But calculating aggregates in a relational database leads to full table scans. Such operations are not only slow themselves but also harm the performance of parallel requests, in particular write requests.
Apart from that, you could pre-calculate the requested data and store the results separately. But refreshing the calculations is costly, in particular if masses of data are involved, and it might take a while until new data shows up.
In addition, you might need to change the set of collected data regularly. But changing the schema of a relational database can lock a relational database for hours if a table is already very large.
* * *
Therefore:
Choose a Column Family Store, which can store masses of structured data by partitioning the data at a column-level. All read operations and calculations on individual columns are very fast. Adding and removing columns are cheap operations.
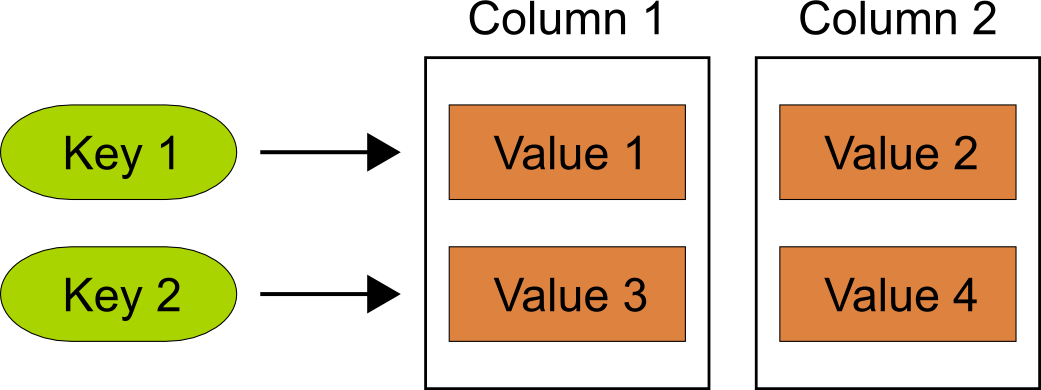
A Column Family Store keeps data in columns rather than rows. The values of a column are kept in a contiguous space on the physical storage. The database can quickly retrieve all values of a column and perform operations on them. The less the values in a column vary, the better the content of a column can be compressed. The compression alone can lead to an improvement in an order of magnitude to row-based data stores.
New columns can easily be added and existing columns can be easily deleted even if the database already holds large amounts of data. On the downside, the values of a data set are spread among several columns. Inserting, updating or reading the complete data set can be more time-consuming than in a relational database as the data columns may even be distributed even among multiple machines.
A Column Family Store can be seen as a Key/Value Store where data is stored in a format ready to be consumed and analyzed very efficiently.
Examples of Column Family Stores are HBase and Cassandra.
Back to the pattern overview